
使用因子增强 MIDAS 在 Covid-19 期间临近预报美国 GDP
COVID-19 大流行在全球经济中掀起了波澜,引发了宏观经济冲击,并为试图预测当前经济状况的经济学家带来了前所未有的挑战。
为了更及时、更准确地评估 COVID-19 时代的经济状况,经济学家和研究人员转向创新解决方案,出现了最有前途的技术之一:MIDAS(混合数据抽样)估计。
MIDAS最初于2000年代初开发,作为以更高频率临近预报GDP的有力工具而受到关注,从而实现更明智和及时的决策。
我们之前在此博客上介绍过临近预报和 MIDAS with EViews。我们已经展示了如何将新颖的 MIDAS-GETS 方法与 PMI 数据结合使用来准确临近预测欧元区 GDP,并且我们已经展示了如何使用主成分将每日序列简化为一小组变量,然后使用 MIDAS 来临近预测澳大利亚 GDP。
这篇博文与上面的后一篇文章类似——我们将使用大量高频变量,通过变量减少和MIDAS估计的组合来临近预测GDP。具体来说,我们将使用美国宏观经济变量的 FRED-MD 月度数据库来预测美国 GDP,使用因子增强 MIDAS 模型。
目录
- 介绍
- 数据
- 临近预报 2020Q2 GDP
- 长期临近预报评估
- 文件
- 引用
介绍
有关MIDAS的背景及其优势的介绍,请参阅我们之前的博客文章。在这篇文章中,我们将执行因子增强 MIDAS (FA-MIDAS),这是对标准 MIDAS 技术的扩展。FA-MIDAS是在Marcellino和Schumacher(2010)中引入的,并已用于许多不同的研究,包括Gül和Kazdal(2021)以及Ferrara和Marsilli 2018。
传统MIDAS的缺点之一是它无法处理大量的高频回归器。事实上,通常建议只使用单个高频回归器。随着当今数据的丰富,经济学家面临着大量高频回归因素可供选择,将变量数量减少到单个或少量变量是一项艰巨的任务。
因子分析能够通过识别回归变量之间的相关性来降低回归变量的维数,并使用这些相关性创建一小组潜在因素,这些潜在因素包含与原始变量集相似的信息。
然后,FA-MIDAS方法是首先使用因子分析将大量高频变量简化为少数潜在因子,然后使用这些高频因子作为MIDAS回归中的回归因子来对低频变量进行建模。
数据
圣路易斯联邦储备银行(Saint Louis Federal Reserve)维护着一个大型的美国月度宏观经济变量数据库FRED-MD。该数据库包含 127 个变量,这些变量每月更新一次,并在单个 .CSV 文件。该数据库的存档版本也可用,这意味着您可以下载特定月份发布的数据(即不包含自该日期以来所做的任何修订)。该数据库还包含一个附录,该附录指定了在用于分析之前应对每个序列执行的适当转换。转换包括第一和第二差异、对数以及第一和第二对数差异,以及根本没有转换。
除了使用该数据库外,我们还将访问FRED的美国季度GDP数据,这些数据也可以在存档的基础上检索 – 使用历史上某个日期的可用值。
临近预报 2020Q2 GDP
我们可以想象我们是在 2020 年 6 月,也就是美国 Covid 数字最初激增几个月后。这是2020年第二季度的最后一个月,因此我们还没有该季度的任何官方GDP数据。但是,我们将从 FRED-MD 数据库中获得截至 2020 年 5 月的美国数据。这意味着在 2020 年 3 月开始的 Covid-19 关闭之后,我们有两个月的宏观经济数据,但在 Covid 期间没有 GDP 本身的数据。
我们将介绍根据月度数据生成 GDP 临近预报所采取的步骤。
首先,我们将指示EViews下载2020年6月的FRED-MD数据库。我们可以从 FRED-MD 网站手动下载此文件:
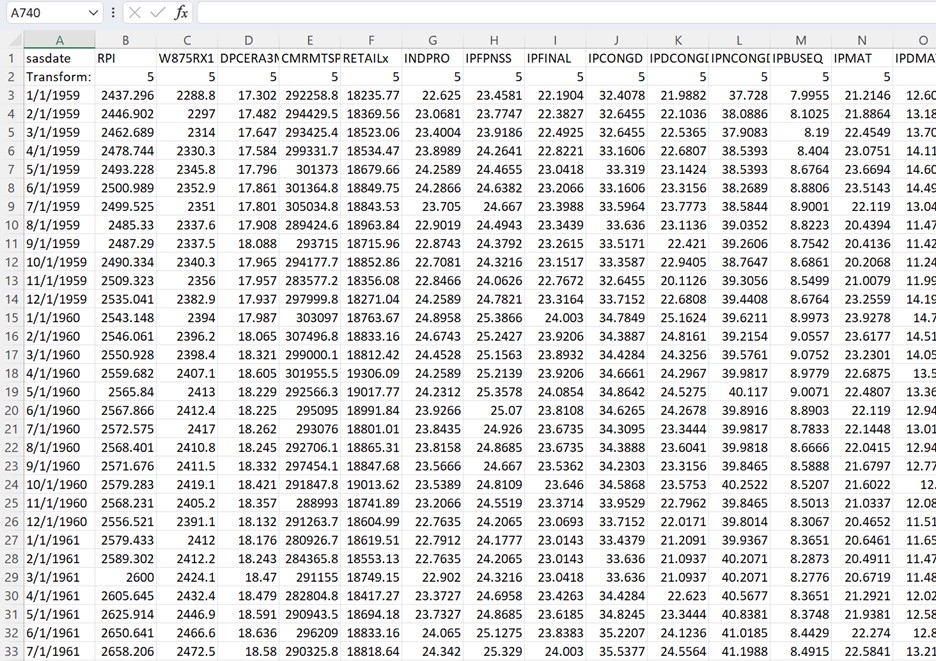
但是,由于数据库是一个简单的.CSV 文件,我们可以指示 EViews 使用 wfopen 命令直接从互联网打开文件:
我们只需在 wfopen 后面加上文件的 url,然后添加两个参数来描述数据——第一个参数告诉 EViews 文件顶部有两行标题(系列的名称, 和转换),以及这两行标题的名称,名称位于第一行,后跟系列属性(在我们的示例中为转换)。wfopen https://files.stlouisfed.org/files/htdocs/fred-md/monthly/2020-06.csv
此导入的一个问题是,尽管 CSV 文件中的第一列 sasdate 包含日期,但 EViews 无法将该文件识别为已注明日期。这是因为 CSV 文件末尾包含一行空白信息,EViews 无法识别该空白信息。单击“Proc->Structure/Resize Current Page”,然后将Workfile structure type”更改为“Dated – specified by date series”,并输入 sasdate 作为 Date series,即可轻松解决此问题:
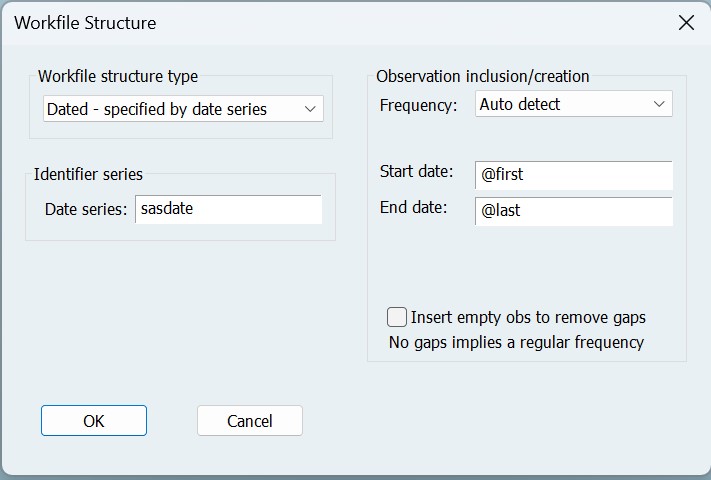
然后,EViews 会警告我们从工作文件(空白行)中删除一个观察结果,但在确认这是我们想要做的事情后,我们最终会得到一个结构良好的月度工作文件,其中包含 1959 年至 2020 年 5 月之间的所有 127 个变量。

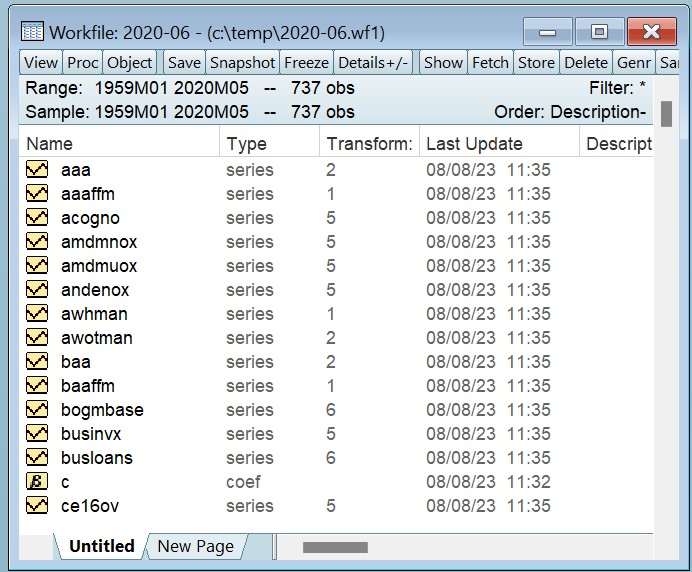
因为我们将CSV文件的转换行作为属性导入(带有命令的参数),所以每个序列还包含关于推荐的转换类型的元数据。我们可以通过使用工作文件上的Details +/-按钮来查看它们,然后通过右键单击任何列标题并选择Edit columns来添加转换列
namepos=firstatt
wfopen
EViews 中没有点击式方法可以自动将转换一次应用于所有序列。但是,我们可以制作一个简单的程序来遍历每个序列,从其属性中提取转换类型,然后将转换应用于自身:
仅部分序列缺少去年的一些数据。我们希望从我们的分析中删除这些 – 我们宁愿只使用具有完全最新数据的系列。我们将进行另一个快速循环,根据组是否有去年的观测值将序列添加到组中。 现在我们准备对我们的组进行因子分析。
为此,我们可以打开我们创建的组 G,然后单击 Proc->Make Factor 以显示 Factor Specification 对话框。在 EViews 中执行因子分析时,可以指定很多很多选项,但我们会将其中大多数选项保留为默认值。我们要进行的唯一更改是更改因子数选项以使用 Ahn 和 Horenstein 方法(此方法往往比其他方法产生更少的因子,这在执行 MIDAS 估计时很有用)。
'perform transformations
%serlist = @wlookup("*", "series")
for %j {%serlist}
%tform = {%j}.@attr("Transform:")
if @len(%tform) then
if %tform="1" then
series temp = {%j} 'no transform
endif
if %tform="2" then
series temp = d({%j}) 'first difference
endif
if %tform="3" then
series temp = d({%j},2) 'second difference
endif
if %tform="4" then
series temp = log({%j}) 'log
endif
if %tform= "5" then
series temp = dlog({%j}) 'log difference
endif
if %tform= "6" then
series temp = dlog({%j},2) 'log second difference
endif
if %tform= "7" then
series temp = d({%j}/{%j}(-1) -1) 'other
endif
{%j} = temp
d temp
endif
next
%serlist = @wlookup("*", "series") 'get list of series
smpl @last-11 @last 'set sample to last year of observations
group g 'declare a group
for %j {%serlist} 'loop through series
if @obs({%j})=12 then 'if series has values for every observation in last year
g.add {%j} 'add it to group
endif
next
smpl @all 'reset sample to everything
在本例中,分析导致创建单个因子。我们可以通过单击 Proc->Make Scores,然后单击 OK 将此因子作为系列输出到工作文件中。
这将在我们的工作文件中生成一个新序列 F1,我们将在 MIDAS 估计中将其用作高频回归器的序列。
在继续处理低频数据之前,我们将快速为每月页面提供一个比默认的“无标题”更具描述性的名称,方法是右键单击页面选项卡,选择“Rename Workfile Page…”,然后输入“Monthly ”作为新名称。
要设置我们的季度 GDP 数据,我们单击“新建页面”选项卡,然后选择“Specify by Frequency/Range…“,然后,我们将选择“季度频率”,并将开始日期更改为 1992 年(尽管在此日期之前我们有每月变量的数据,但我们将减少估计中实际使用的数据量)。我们将该页面称为“Quarterly”。
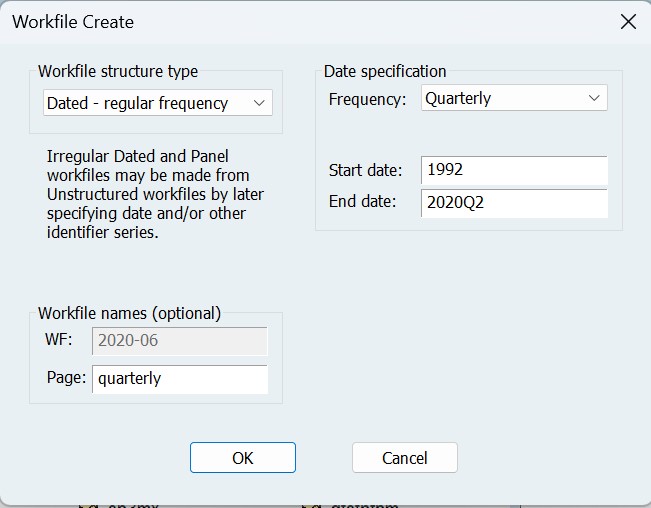
创建页面后,我们将打开 FRED 数据库 (File->Open->Database->FRED),浏览并搜索 GDP,将As Of: 日期更改为 2020-06-01,然后将实际 GDP 系列拖到我们的工作文件中。本系列包含 2020 年 6 月可用的美国实际 GDP 数据(不是今天可用的数据)。EViews 会询问我们是否要更改名称(因为源名称在 EViews 中是非法的)。我们将它更改为 GDP。
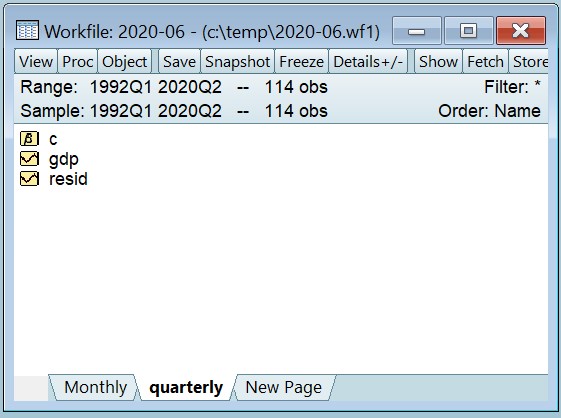
如果我们打开GDP序列,我们可以看到2022年第二季度的最终值是NA–2020年6月1日,GDP值尚未公布。
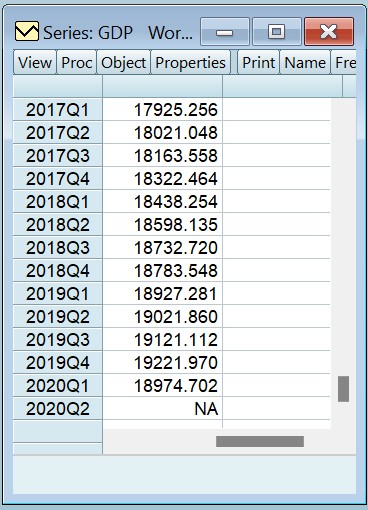
现在,我们已准备好执行 MIDAS 估计,方法是单击“Quick->Estimate Equation>然后单击“Method ”下拉列表,将“Method ”下拉列表更改为“MIDAS”。GDP模型通常使用GDP的百分比变化作为因变量,将GDP的百分比变化的常数和单一滞后作为季度回归因子。我们可以使用 EViews 中的函数计算百分比变化。
@pch
高频回归器的规格需要稍加思考。我们希望使用月度序列 F1(这是我们之前创建的因子序列)作为我们的高频回归因子。我们有截至 2020 年 5 月的 F1 数据,即 2020 年第二季度的第二个月。在MIDAS估计期间在高频和低频数据之间进行转换时,默认情况下,EViews将使用该季度的最后一个观测值,并从那里开始向后工作。在我们的例子中,这将是 2020 年 6 月,但在我们创建的月度页面中,这个月不存在(月度页面在 2020 年 5 月结束)。解决此问题的最简单方法是将估计对话框的“Options ”选项卡上的“MIDAS估计的频率转换”设置更改为“First”。现在,EViews 将使用本季度第一个月的数据,而不是最后一个月的数据。
这将使我们能够产生估计。但是,我们实际上会丢失一些信息——我们将使用 2020 年 4 月(4 月是该季度的第一个月)及更早的数据,并在 2020 年 5 月删除信息。我们可以通过将每月回归器输入为 monthly\F1(1) 来缓解这种情况,其中 (1) 表示将数据从每月的第一天转移到一个月。我们将选择使用 F1 系列的 12 个月滞后(一整年)。
这意味着,例如,2019 年第三季度的 GDP 数据将由 2019 年第二季度的 GDP 数据(GDP 的一个时期滞后)来解释,这是 2018 年 9 月至 2019 年 8 月(2019 年第三季度的第二个月)的 F1 常量月度数据。

估计的结果是:
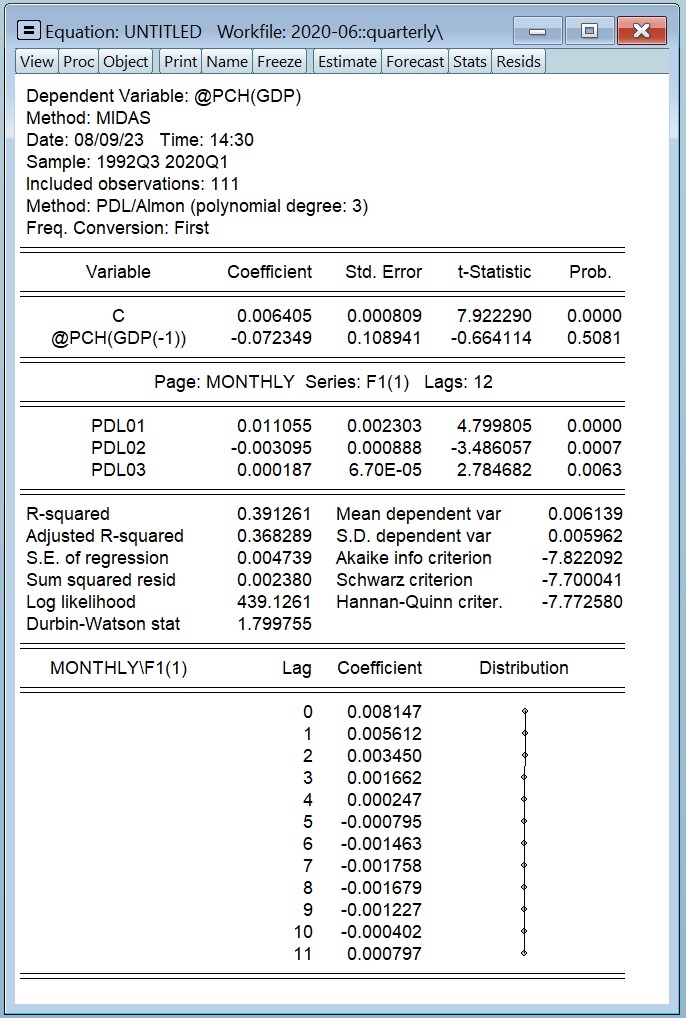
我们可以看到,三个 MIDAS PDL 系数在统计意义上都显著。另请注意,EViews 自动将估算样本调整为 2020 年第一季度结束(这是我们获得 GDP 数据的最后一个季度)。
要临近预报 2020Q2 GDP,我们现在要做的就是单击“预测”按钮,并将预测样本设置为 2020Q2 2020Q2(相同的开始日期和结束日期意味着预测单个时期)。
请注意,尽管该方程是根据 GDP 的百分比变化来指定的,但我们将预测 GDP 的原始值,而不是百分比变化,并且预测值将放入 GDPF 序列中。由于我们选中了“Insert actuals for…”复选框,因此该系列将包含非预测期(即 2020Q2 以外的每个季度)的 GDP 实际值。单击“OK”后,我们可以将 GDPF 系列作为图形打开:
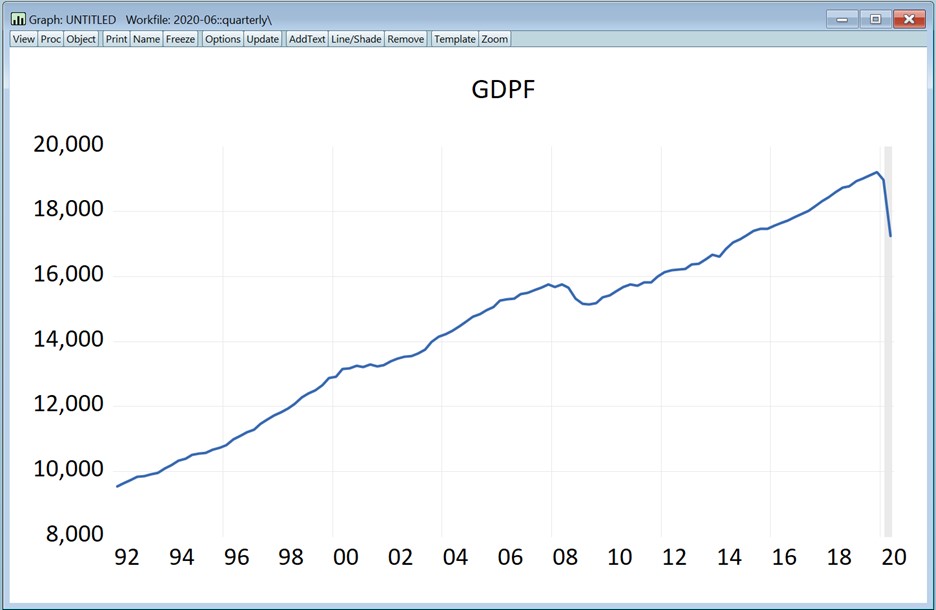
我们可以看到,图表的预测(阴影)区域 GDP 急剧下降,这与经济预期相匹配。
我们可以更进一步,通过检索该时期的GDP实际值来实际衡量2020Q2 GDP的临近预报有多好。为此,我们再次打开 FRED 数据库,将“As of:”日期更改为 2020 年 8 月,然后将 GDP 系列拖回 EViews。我们将保留 EViews 建议的名称,以识别数据截至 2020 年 8 月。我们可以将这个系列与临近预报系列一起打开,然后使用图表滑块放大最后几个季度的数据来查看图表:
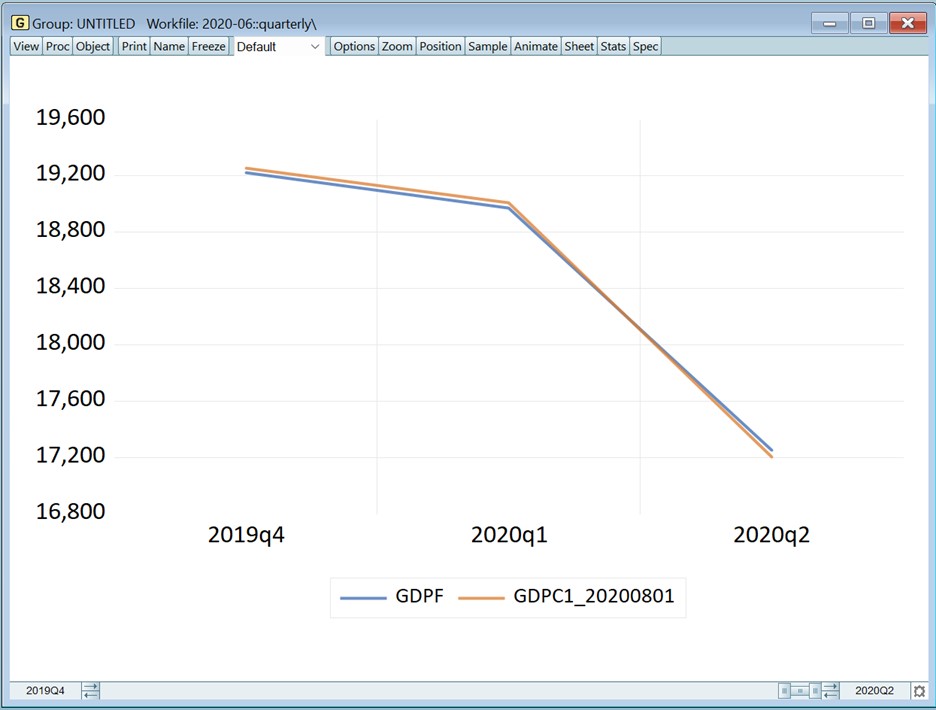
我们可以看到,2020年第二季度的临近值(蓝线)与实际值(橙色)非常接近!
长期临近预报评估
在上一节中,我们介绍了如何预测单个季度的GDP,并显示了预测值非常接近首次发布的实际数据。作为一个单一的结果,这并没有决定性地告诉我们,临近预报模型总是一个准确的预测。为此,我们需要在更长的时间内执行一系列即时预测,并将一系列即时预测的结果与实际数据进行比较。
通过EViews编程语言,在EViews中执行这样的研究相对简单。我们已经编写了这样一个脚本,现在预测2017年1月到2023年7月之间的GDP。我们不会遍历脚本的每一步,但会描述它的功能。
数据检索
该程序在 2017 年到今天之间每个月循环播放。对于每个月份,它都会将该月的 FRED-MD 文件下载到工作文件中的新页面中。因此,每个月都有自己的页面,其中包含从 1991 年到前一个月的 FRED-MD 数据(例如,因为 2020-06 年的 FRED-MD 文件包含 1991 年至 2020-05 年的数据)。
对于循环中的每一个月,程序还会将季度 GDP 从 FRED 下载到季度页面,其中 GDP 数据截至当月第一天(因此将包含截至当月季度前一个季度的数据,甚至可能包含前一个季度的数据,具体取决于 GDP 数据正式发布的延迟时间)。
估计
检索到数据后,对于循环中的每个月,都会在每月的 FRED-MD 数据集上估计一个因子模型(删除了不包含前两年数据的任何序列),并将估计的因子输出到每月页面。然后,对于截至该月的相应季度 GDP,估计 MIDAS 模型,以百分比变化的 GDP 为因变量,以百分比变化的 GDP 的常数和滞后为回归因子,并使用因子序列的 12 个滞后和多项式阶数 3 的 Almon/PDL 加权 MIDAS 项。对于每个月份,频率转换都设置为“first”,因子序列向前移动以允许捕获最多的数据(就像我们之前执行的单次估计一样)。
同时,还估计了 GDP 的简单 AR(1) 模型的基线比较模型(即简单地将 GDP 的百分比变化与常数和滞后回归)。
临近预报
对于MIDAS估计和基线AR模型,将进行一个周期的提前临近预报,并存储该季度的两个值。
在该计划每个月循环播放后,每个季度将有三个临近预报,适用于两个模型。第一个临近预报将对应于本季度第一个月的数据,第二个临近预报将对应于本季度第二个月的数据,第三个临近预报将对应于本季度第三个月的数据。
这些临近预报存储在每月的页面中,提供逐月更新的季度 GDP 临近预报。
我们还会将这些临近预报复制到季度页面,取每个季度三个月预测的平均值。
结果
下图显示了 FA-MIDAS 模型 AR(1)模型生成的月度临近预报的时间序列,以及截至首次发布的实际 GDP 数据:
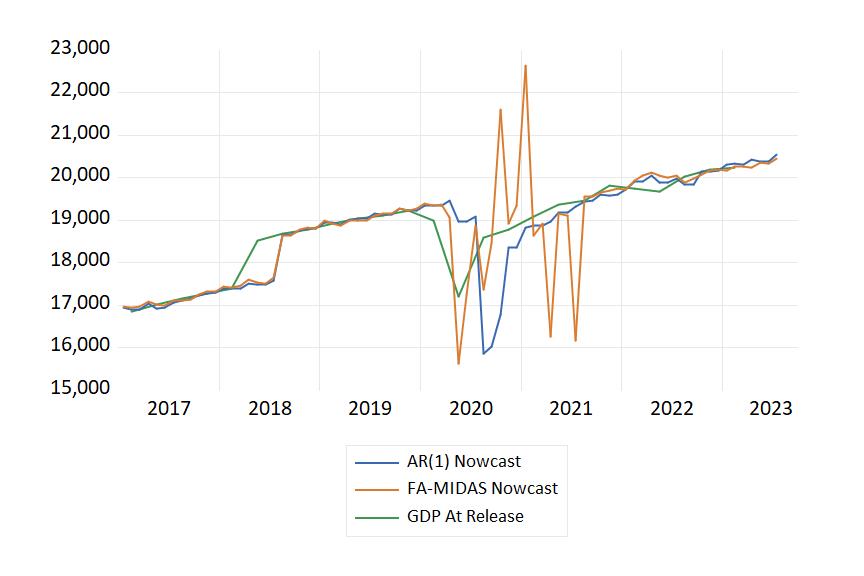
我们可以看到,MIDAS临近预报在COVID期间波动很大,这无疑是由于当时经济的不稳定。然而,与AR(1)模型相比,它确实正确地安排了2020年初GDP急剧下降的时间,即使它确实大幅超调。
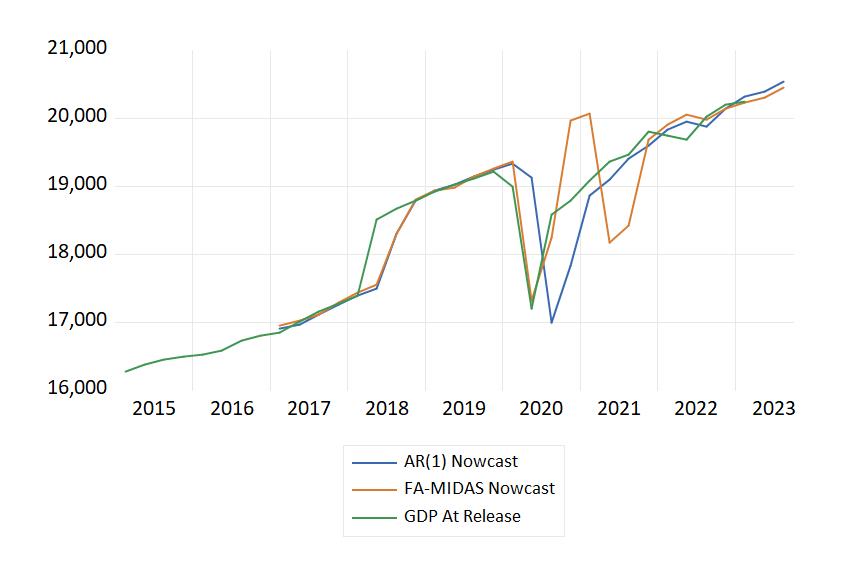
查看同一张图表的季度版本,我们可以看到 MIDAS 方法与 COVID 第一年的实际 GDP 非常接近,但波动幅度又有点太大。
该脚本还会生成两个预测的预测评估表,以及两个预测的简单平均值:
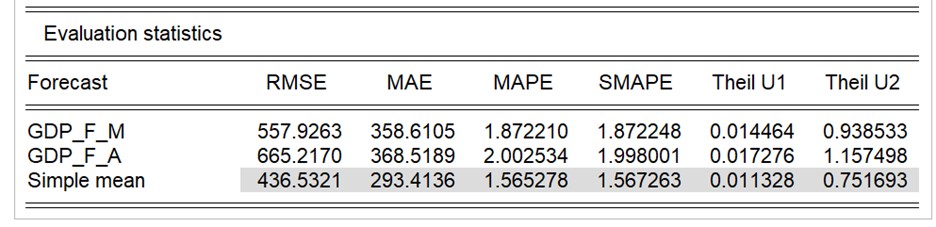
两个预测的平均值表现最好,但在这两个预测中,FA-MIDAS模型产生的预测更准确。
文件
引用
- Ferrara,L.和Marsilli,C.(2018)。临近预报全球经济增长:因子增强的混合频率方法。世界经济。
- Gül, E., & Kazdal, T., (2021)。COVID-19 大流行、疫苗接种和家庭支出:来自土耳其信用卡数据的区域证据 应用经济学快报,1-4。
- Marcellino,M.和Schumacher,C.(2010)。用于临近预报和预测的因子MIDAS与不规则数据:德国GDP经济统计的模型比较,72.4:518-550。